Dox Accuracy; DRY AI; Wood-ent You Like to Know?
Today is a day of the year when a freakishly large part of the United States waits with great anticipation for some old, costumed codgers to torture a poor member of the Sciuridae family in a futile effort to predict how much longer we will have to suffer through the Winter season.
It also an event that has been memorialized in film, causing “Groundhog Day” to become part of the English lexicon, recognized as shorthand for a monotonous, unpleasant, and repetitive situation.
So, today we take a glimpse at the data behind the dox, along with some resources to help avoid Bill Murray’s fate.
Dox Accuracy
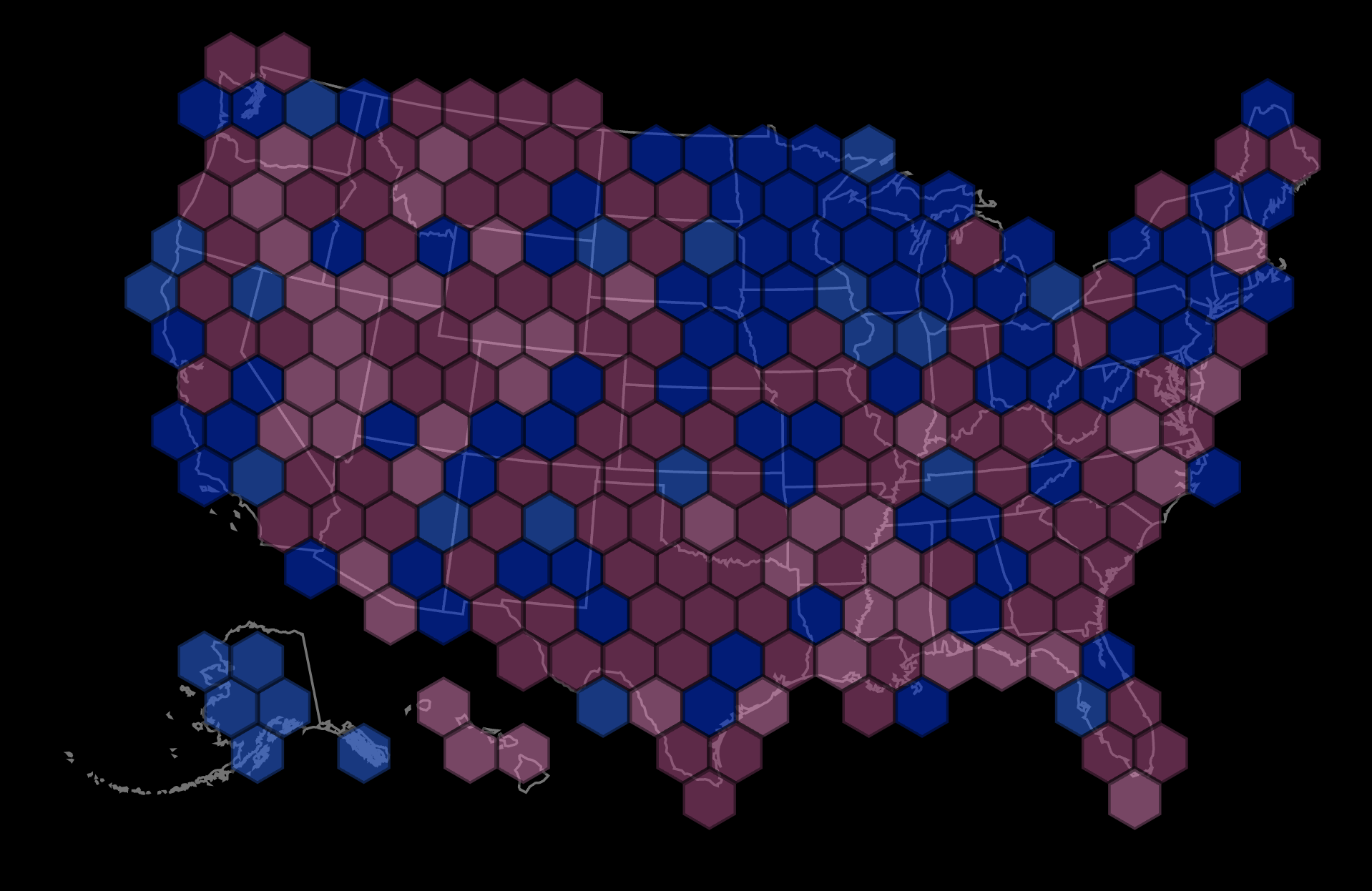
For a supposedly advanced civilization, we devote an odd amount of time, money, and attention to this annual, unscientific prediction endeavour. Back in 2015, a team at Washington Post decided to do some maths on Punxsutawney Phil. They explored the relationship between the famous dox’s predictions and a given U.S. region’s temperature fluctuations during the six weeks after February 2 in each year. They started with the premise that years in which Phil saw his shadow would be colder than non-shadow years because, in shadow years, Phil predicts six more weeks of winter rather than an early spring.
Here are some more details regarding their research methods:
For the past 30 years, we calculated the average daily temperatures during the six weeks after Groundhog Day for years in which Phil saw his shadow and compared them to temperatures of non-shadow years. With these averages we calculated something called a t-statistic, which takes into account the variations in temperatures within each region, and also indicates the statistical significance of our findings. These t-statistics determined whether Phil’s predictions were more or less correct in a given area as indicated in the color code in the map above.
The map in the section header shows the results, but you’ll have to tap the fine article to see what the [inverted] colors mean. (Spoiler alert: Phil should be fired.)
LiveScience also has a bit more info on Phil’s accuracy
DRY AI

Before we get to the actual resource, I asked ChatGPT to write a blog post about the DRY principle. The results are below the blockquote. Said blockquote is what ChatGPT’s new AI classifier for indicating AI-written text — mentioned in the previous Drop — spit back after inputting the text into it. So not-helpful. (Unless you’re not familiar with the DRY principle or are morbidly curious about what our trendy stochastic parrot, feel free to skip down to the good bit).
The classifier considers the text to be possibly AI-generated.
DRY (Don’t Repeat Yourself) is a software development principle that states that code should not have redundancy or repetition. It means that every piece of information should have a single, unambiguous representation within the codebase. The DRY principle was introduced by Andrew Hunt and David Thomas in their book “The Pragmatic Programmer”. The main idea behind DRY is to eliminate duplication and simplify the maintenance of code by ensuring that every piece of knowledge is expressed in only one place.
The benefits of adhering to the DRY principle are many. One of the main advantages is that it reduces the chances of bugs being introduced into the code. If a piece of code is repeated in multiple places, changing it in one location may not have the desired effect in all other places, leading to potential inconsistencies. By ensuring that every piece of information has a single representation, bugs are easier to locate and fix.
Another benefit of DRY is that it makes the codebase easier to maintain. Since all information is expressed in a single place, changes can be made more easily without having to make the same change in multiple locations. This reduces the risk of introducing new bugs and also makes it easier for others to understand and maintain the code.
DRY also helps to improve code readability. By reducing code redundancy and repetition, the codebase becomes easier to understand and navigate. This makes it easier for developers to work on the code and understand how it fits together. It also reduces the risk of confusion, which can result in wasted time and effort.
👉🏼 The Good Bit
Strange company name aside, the Hugging Face folks are a clever lot, and have already made quite a mark on our slice of the 21st Century (I hope they plan to clean that up, too). HF’s Patrick von Platen posted a short piece on designing open-source libraries for modern machine learning, titled “Don’t Repeat Yourself”. Here’s the setup:
At first glance, the design of Hugging Face’s Transformers library couldn’t be more contrary to the DRY principle. Code for the attention mechanism is more or less copied over 50 times into different model files. Sometimes code of the whole BERT model is copied into other model files. We often force new model contributions identical to existing models – besides a small logical tweak – to copy all of the existing code. Why do we do this? Are we just too lazy or overwhelmed to centralize all logical pieces into one place?
No, we are not lazy – it’s a very conscious decision not to apply the DRY design principle to the Transformers library. Instead, we decided to adopt a different design principle which we like to call the single model file policy. The single model file policy states that all code necessary for the forward pass of a model is in one and only one file – called the model file. If a reader wants to understand how BERT works for inference, she should only have to look into BERT’s modeling_bert.py file. We usually reject any attempt to abstract identical sub-components of different models into a new centralized place. We don’t want to have a attention_layer.py that includes all possible attention mechanisms. Again why do we do this?
There are four main reasons:
HF “Transformers” is built by and for the open-source community.
HF’s products are models and their customers are users reading or tweaking model code.
The field of machine learning evolves extremely fast.
Machine Learning models are static.
It’s an informative read that also is open about the drawbacks to their choice and the whole piece may help you if you’re in a quandary regarding how to apply DRY to AI.
Wood-ent You Like to Know?

(Yes. I’m stretching today’s theme a bit thin in this last section.)
The dox (groundhog) is also sometimes referred to as a woodchuck, and you’ll be glad? to know that, back in 2019, science finally answered an age-old burning question about these furry beasts.
FIN
Here’s hoping that only the good parts of today repeat for you. ☮

Leave a comment